Method
Two rotations, one identity, zero reparameterization.
The core update rule
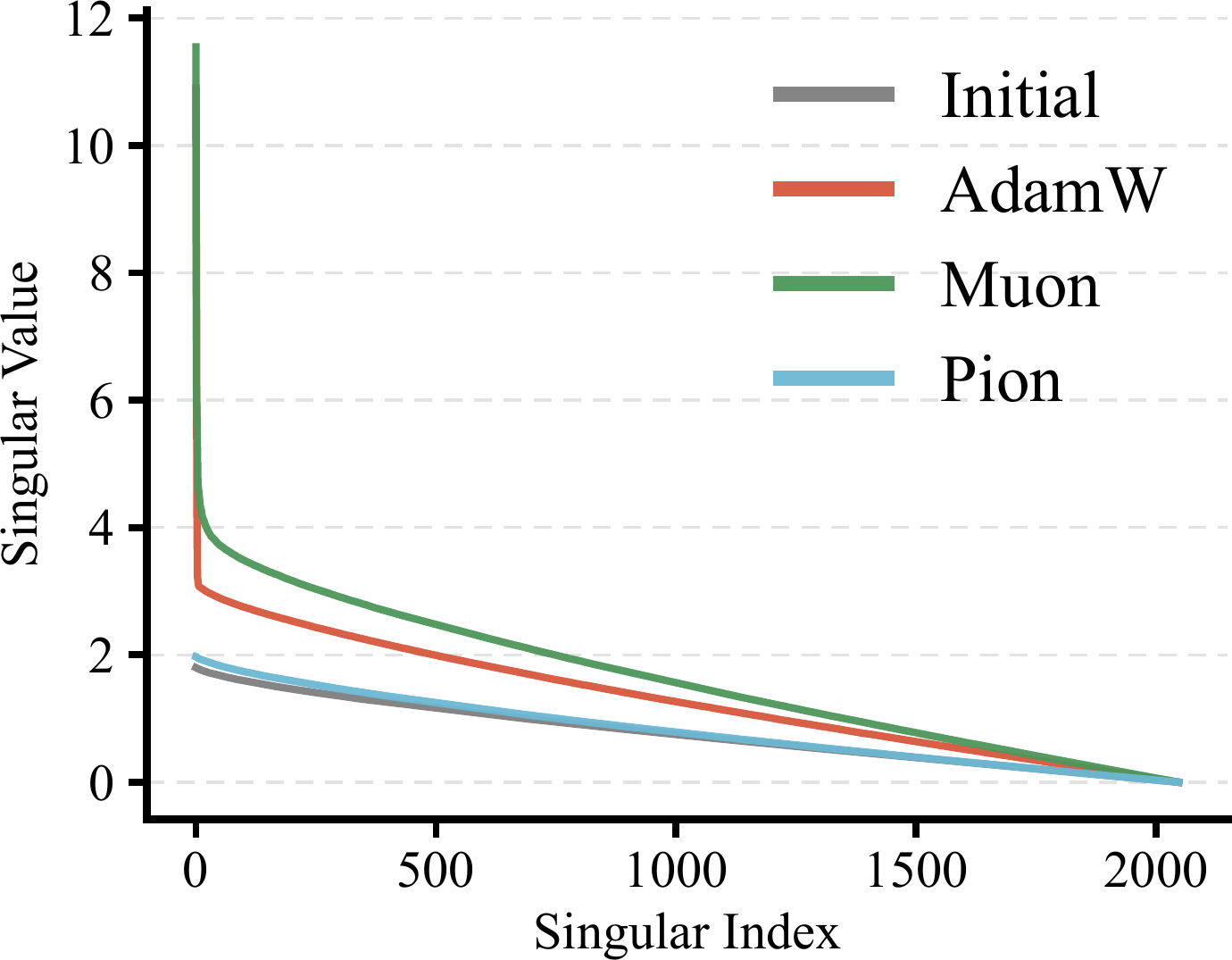
For any weight matrix Wt ∈ ℝdout×din, we can trivially write Wt = Idout Wt Idin. Geometrically, each identity is the neutral element of an orthogonal group. Pion evolves these identity factors directly on the orthogonal group, which induces left and right orthogonal transformations on Wt — preserving its singular values.
The skew-symmetrization projects the gradients onto the Lie algebra; the matrix exponential maps them back to the Lie group, producing valid orthogonal transformations. Because Rt = exp(−η Gtout) and Pt = exp(−η Gtin) are orthogonal, the row and column ℓ2 norms of Wt are preserved — the update is pure angular motion rather than rescaling.
Full algorithm
Design principles for practical training
We turn the bare rule above into a usable optimizer by studying four design axes empirically:
- Consistent updates. RMS-controlled per-weight scaling keeps rotational magnitudes scale-proportional across matrices and unlocks large learning rates.
- Momentum, the right way. The Lie-algebra variants accumulate the in- and out-side skew-symmetric gradients directly inside a single tangent space, sidestepping the parallel-transport problem and matching the geometry of the update.
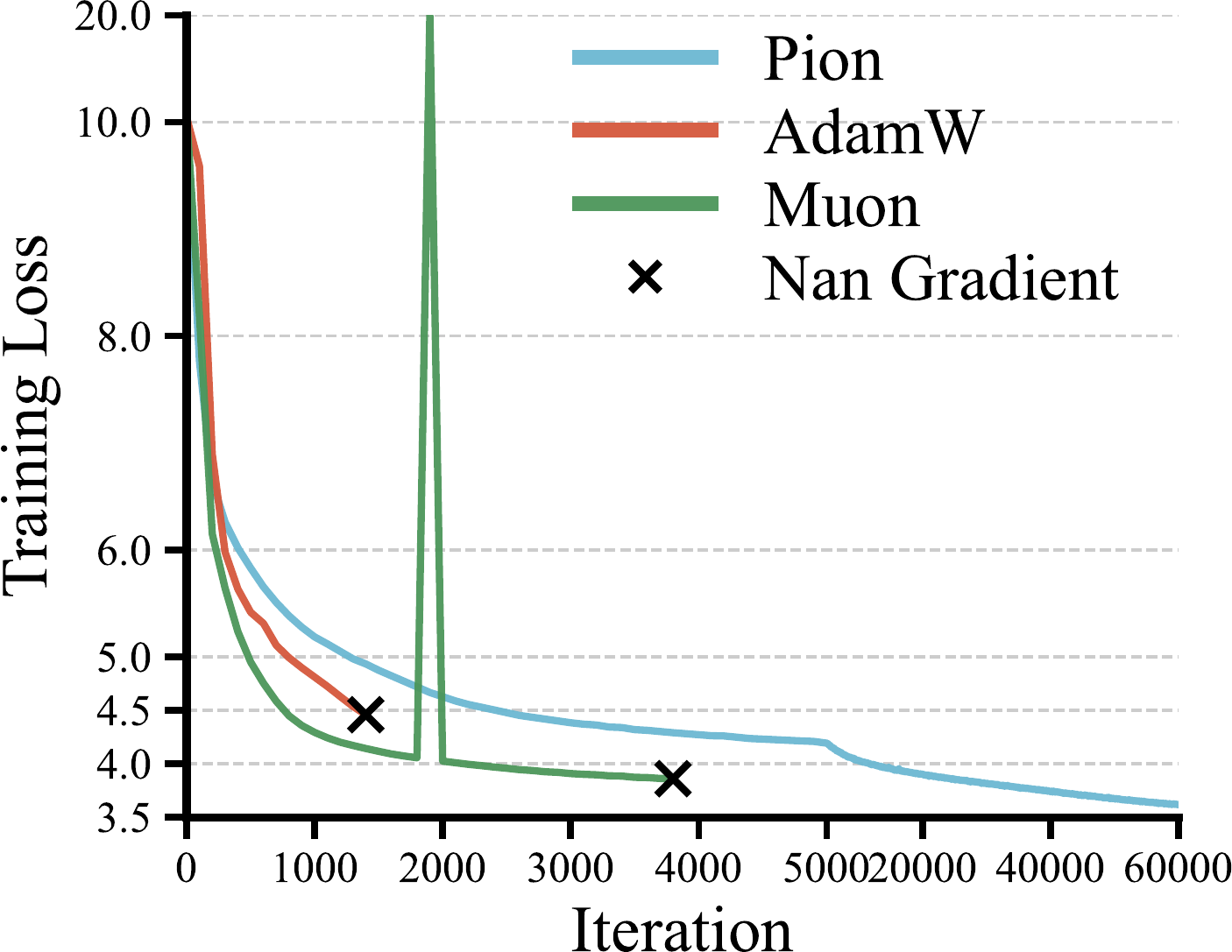
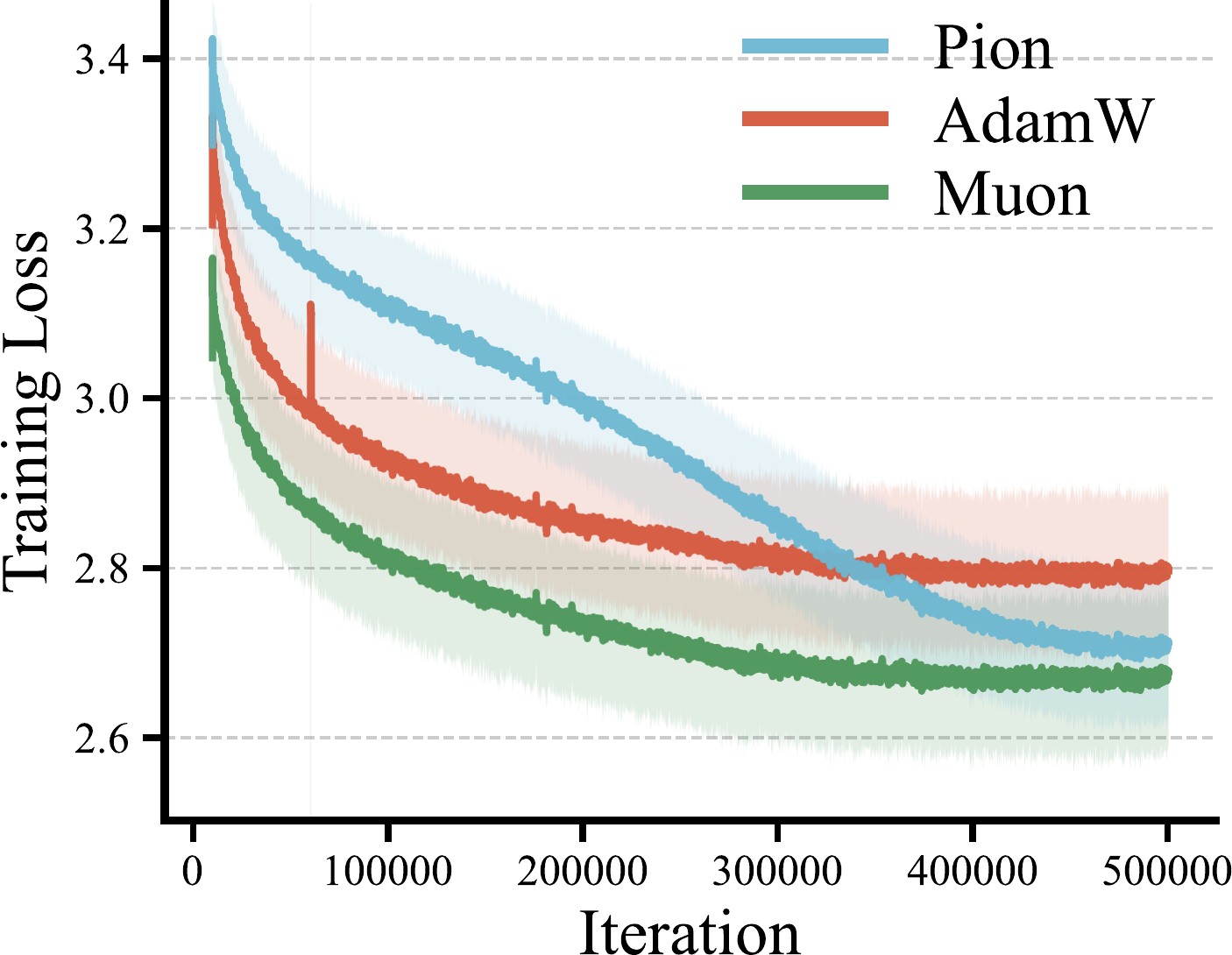
- Alternate updates. Alternating between in-side and out-side rotations across steps stays within ≈ 0.23% of the bilateral training loss while roughly halving the optimizer-side compute.
- Second-order exponential. Each update starts from the identity, so errors do not compound. A two-term truncation exp(A) ≈ I + A + ½ A2 is both sufficient and fast.

Convergence on the iso-spectral manifold
Under standard \(L\)-smoothness, lower-boundedness of \(f\), and bounded stochastic-gradient noise \(\mathbb{E}\| \xi_t \|_F^2 \le \sigma^2\), Pion with step size \(\eta = C / \sqrt{T + 1}\) satisfies:
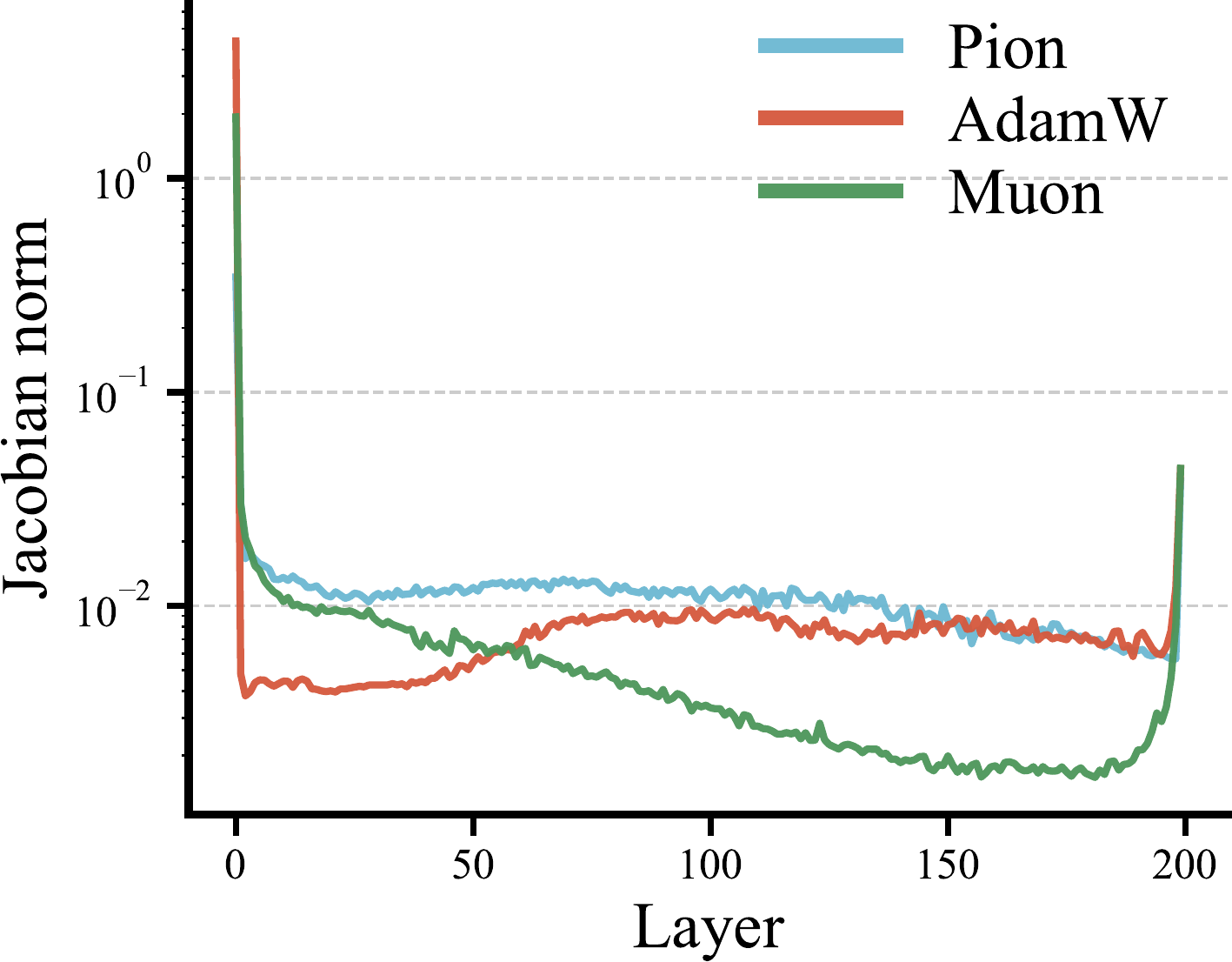
The geometric structure of the update also gives a clean interpretation: the Frobenius norm of ΔW measures the total rotational strength applied to Wt, while the scaled norms ‖Gtin‖F / √din and ‖Gtout‖F / √dout capture the average planar-rotation angles on the two sides.